🧑💻 Configurable Joins from an IT Perspective
IT users dropped into Slate for the first time are often frustrated by Configurable Joins.
What is this goofy tool? How do I create an inner join? 😡
Why Use Configurable Joins
Slate users must understanding Configurable Joins (CJ's). While Slate allows other forms of querying, including direct SQL, Configurable Joins offer many advantages:
- The vendor (Technolutions) recommends and supports them; custom SQL might get broken by schema changes.
- CJ's attempt to naturally steer you towards best practices, towards efficient query plans, and away from strange usage patterns.
- You can build CJ's very quickly once you get used to them.
- CJ's offer some permissioning; all bets are off with custom SQL.
- CJ's are integral to features throughout Slate, like express query contexts (mini-queries sprinkled throughout the product).
- Libraries allow power users to create complex components that other users can re-use.
- CJ's are driven by metadata! When you add a new field or entity (aka table) to Slate, CJ's automatically adapt to the new schema.*
- The broader pool of Slate talent you may wish to hire from is accustomed to CJ's.
*You can't actually alter the [dbo] schema. But Slate does a good job of faking it.
Consider this not-so-far-fetched scenario:
A school has a proficient SQL writer on staff. He writes thousands of lines of complex SQL to integrate Slate with Jenzabar EX, but he does not fully understand the product, so he makes some odd decisions here and there.
The employee departs, and the queries get slow and slower until they fail. Now they must touch the integration queries. The school tries to update them but is preoccupied with migrating to Jenzabar One, so they hire ReWorkflow to create CJ replacements.
The school hopes that we can recreate the output exactly, but we find that inadvisable for reasons like:
- The custom SQL uses complex logic to select the "most important" school record for each applicant, but it sometimes produces the wrong result. We recommend using Slate's built-in School Rank system instead, replacing hundreds of lines with a single
where [rank] = 1and netting a huge performance boost.- The custom SQL papers over a major problem: thousands of duplicate records. Searching for duplicates on-the-fly harms performance as row counts creep up. We recommended merging the duplicates.
- The custom SQL coalesces addresses improperly and could return portions of multiple addresses. Again, we recommend using the built-in ranking system.
- The custom SQL returns columns that for whatever reason are never used by Slate. We put dummy columns in the CJ's to avoid breaking the integration pipeline.
- The custom SQL could output the same transcript multiple times: once per application. Slate's "Configurable Joins - Documents" query base outputs each transcript or other document once, forcing the school to re-evaluate their integration pipeline.
Many difficulties could have been avoided by avoiding custom SQL in the first place. Also, if you don't have good business logic documentation, CJ's are easy much easier to reverse engineer than a thousand-line query.
See Views
CJ Paradigms
Rowcount
The single most important CJ concept is that, unlike traditional SQL, you are not allowed to inflate the rowcount via joins.
Instead of carefully constructing your joins to produce the correct number of rows, you must start from the table that already contains the correct number of rows. All base joins (also called top-level joins) restrict you to one resulting row, typically via left outer join...offset 0 rows fetch next 1 rows only.
Note that you can adjust the offset within your join.

Clauses
The query editor is yet another graphical SQL builder, but we kinda like it. Use that Display SQL button liberally! The clauses are fairly obvious:

Unfortunately, CJ's do not yet offer certain clauses:
unionhaving
Other clauses can only be used as part of subqueries, to avoid altering the rowcount:
group bywindowrank over()
Subqueries and Inner Joins
You already know what subqueries are - Slate uses them a lot. The one-to-many icon usually indicates a subquery:

Subquery Filters, part of the where clause, use operators like exists to reduce the number of rows returned.
Subquery Exports, part of the select clause, give flexibility in returning data.
Confusingly, the one-to-many icon also indicates an inner join in certain contexts, namely when picking a join within a subquery. Here's how to get an inner join:
- Select Join within a subquery
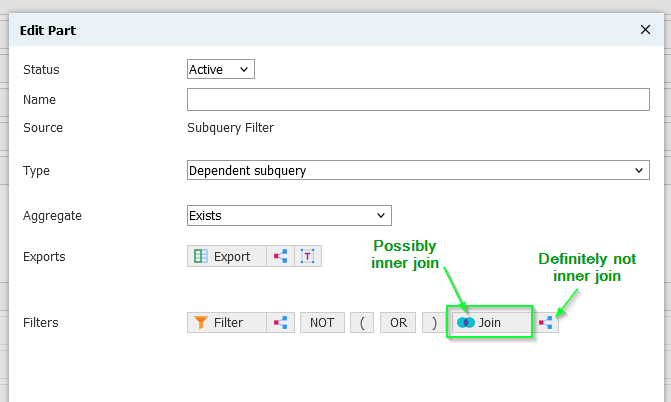
- Pick a table with the one-to-many icon
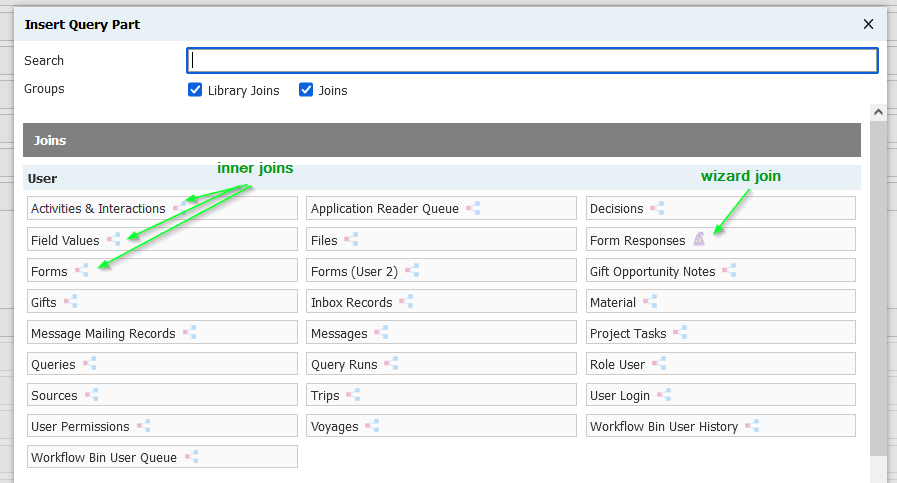
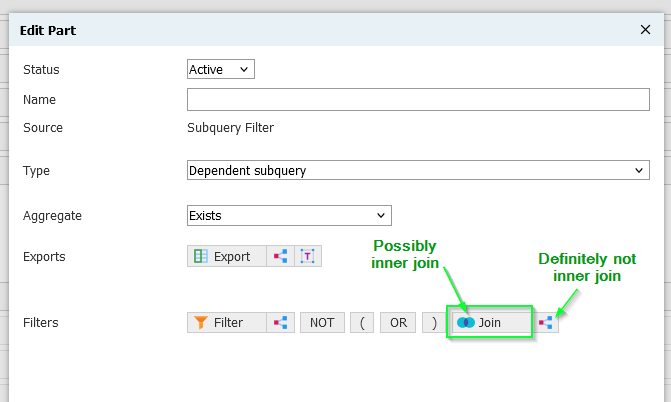
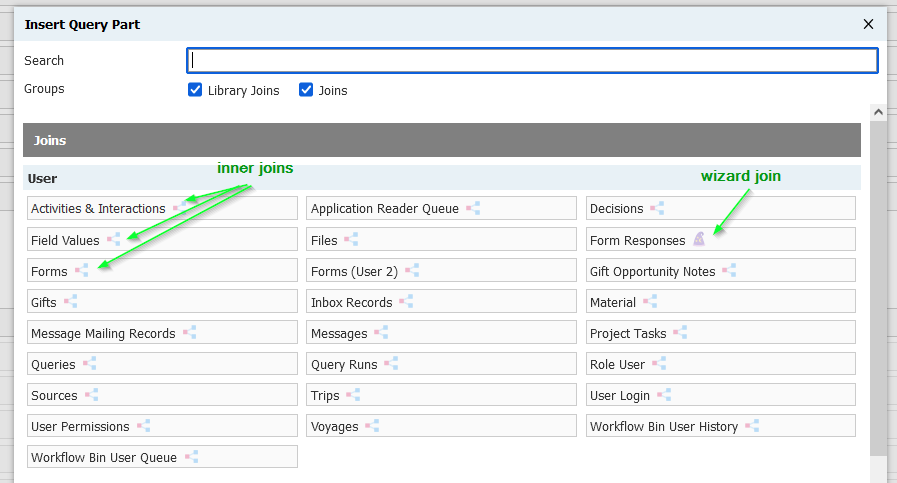
Inner joins are available in most (all?) subquery contexts, but if you use them in exports (select clause), make sure you only get one result, or your query will generate the familiar error, Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
Niceties
There are many handy little tools within CJ's. The Output drop-down in subquery exports has many common functions and usage patterns:
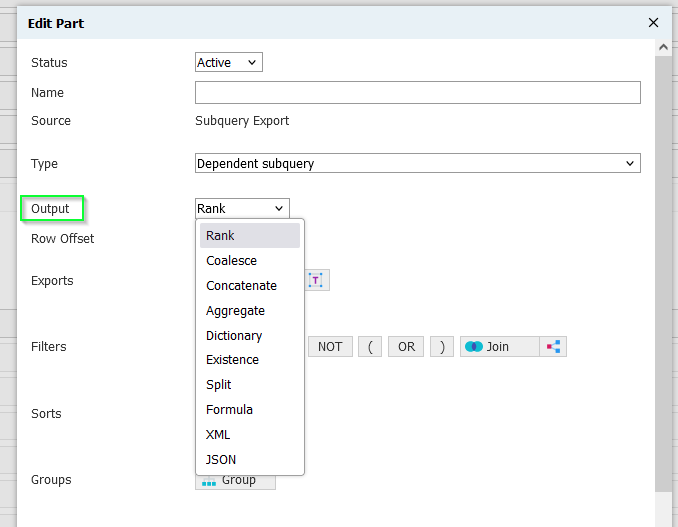
Nearly all exports offer a coalesce() option:
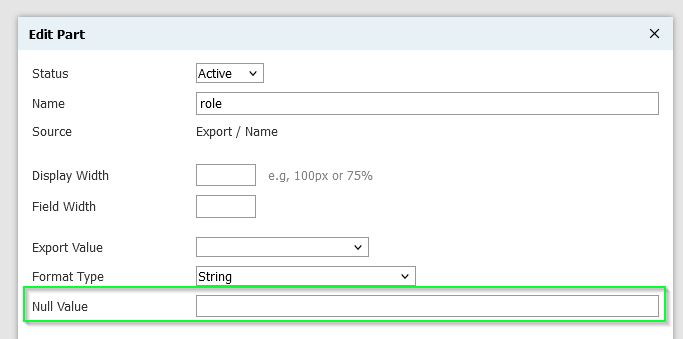
Many export have a try_cast() option:
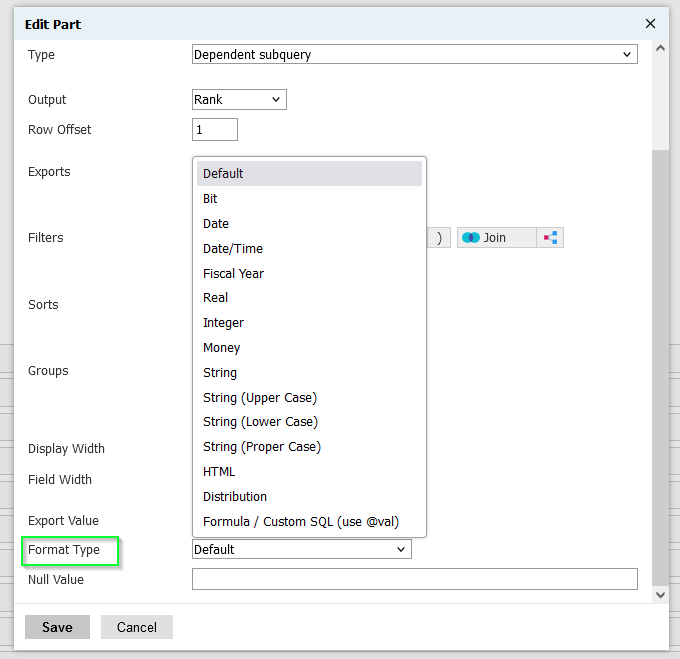
Many exports have a format() option for supported datatypes:
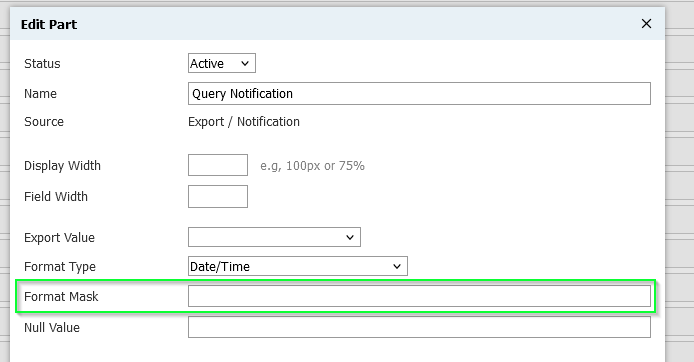
Table Structures
Slate's table structures are solid, although some of the oldest tables have some quirks. Tools for exploring table structures:
- Database > Configurable Joins Base Explorer
- Database > Standard Query Library > Slate Data Dictionary
- Direct SQL connection and SSMS
- Configurable Joins themselves
Most tables use GUID's as the primary key. Many pages in the /manage UI will expose these GUID's in the DOM and often in the URL.
Ranks
Many tables in Slate have one or more [rank] columns created by SQL triggers. See Database Structure & Determination of Table Ranks for more information. We highly recommend embracing the ranking system.
True, there will be a handful of records that don't automatically rank correctly. Rather than writing your own ranking system, which will be slow, utilize built-in mechanisms for correcting ranks in your edge cases. This mechanism is usually a field named Priority.
Test Table
If you need to use custom SQL to pivot and union the [test] table, we won't judge you! All other use cases will start with a presumption of guilt. 😁
Views
CJ queries can output their results to two kinds of "views". Both of these are created via the Schedule Export button in a query. Both objects will appear in the [build] schema.
- Traditional SQL views, known as Dynamic Views
- Tables of pre-computed results, known as Materialized Views. Cron jobs run your query with
SELECT INTOto create a new table. Use cases are similar to indexed views or materialized views in Azure Synapse Analytics.
Use Cases:
- Dynamic Views are suitable for SIS integrations and other direct SQL connections.
- Materialized Views tend to be used as a bailout option when something is too slow for on-the-fly querying, such as expensive analytics. Slate will kill long-running queries on the web nodes after about 30 seconds, but Materialized Views and other background jobs run by worker nodes are allowed 15 minutes.
No comments to display
No comments to display